precomputed-ai
Precomputed AI: Reason Ahead of Time, Serve Instantly
A design pattern for moving LLM reasoning into artifacts produced ahead of time, with live inference reserved for declared escalation paths.
A few weeks ago I wrote about Token Consumption Anxiety — that creeping unease when you watch your AI-powered app burn through tokens, and every user request makes the bill a little bigger.
In that post, I suggested three ways to deal with it. I’ve been sitting with that idea for a while now. It’s bigger than a footnote in an anxiety post. It’s the pattern behind every AI tool I’ve shipped this year.
So I’m giving it a proper name and writing it up properly.
Call it Precomputed AI, or PAI for short.
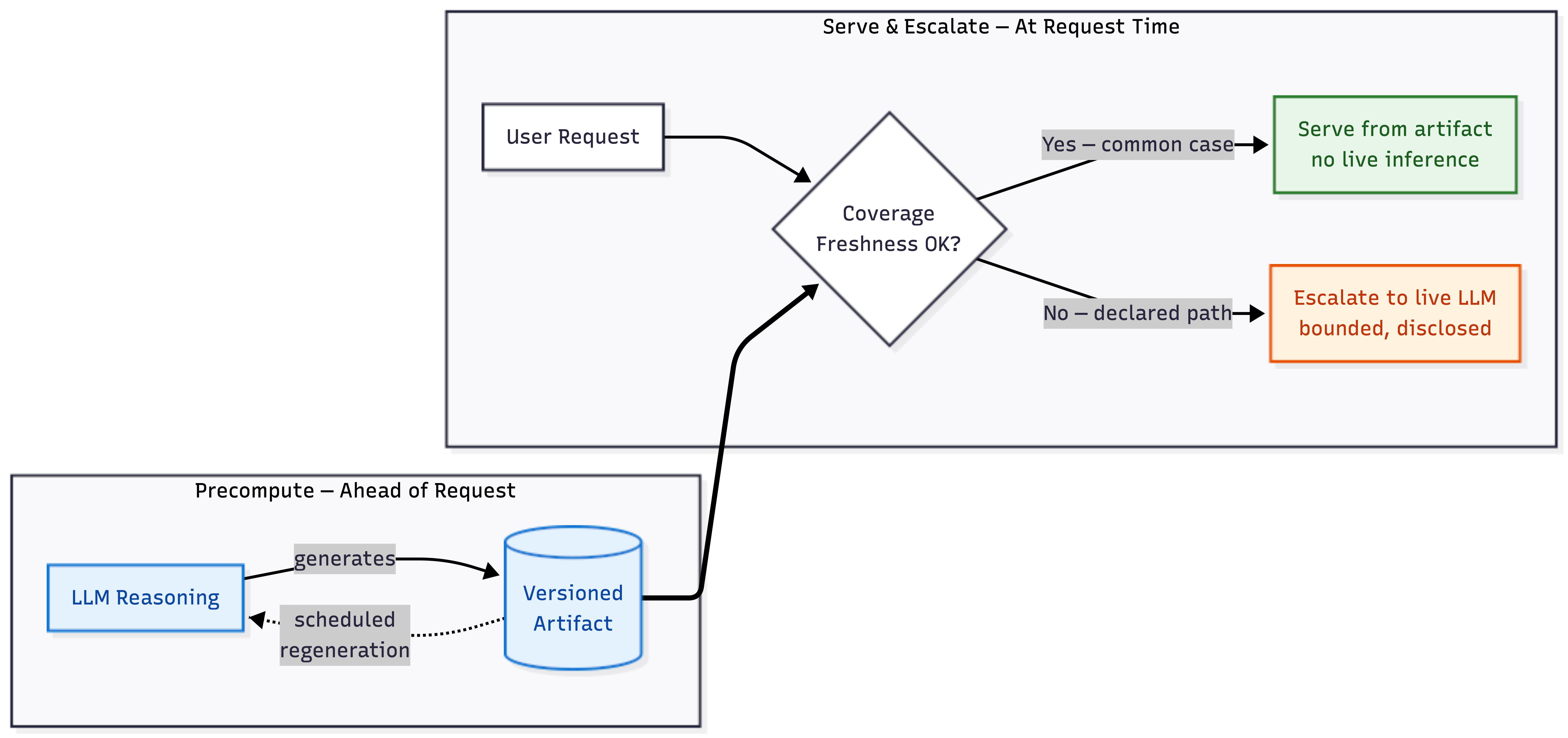
What it is
The idea is simple: use the LLM before your users show up, not while they’re waiting. Bake the reasoning into something you can version, test, and serve instantly. Only call the LLM live when the precomputed stuff can’t handle it.
Three words: precompute, serve, escalate
If you’ve used Next.js static export, Jekyll, or Hugo, this will look familiar. Those tools generate pages at build time and serve them instantly at request time, falling back to dynamic rendering only when they have to. PAI applies the same idea to LLM reasoning.
The artifact doesn’t have to be a web page. It can be a decision ruleset. A lookup table. Generated code. A precomputed explanation. A policy surface. What matters is where the reasoning lives — not on the user’s request, but ahead of it.
PAI is a systems pattern, not an algorithm. It asks where reasoning lives — ahead of the request, or inside it.
What it is not
PAI gets confused with several adjacent ideas. It shouldn’t be.
It’s not caching. A cache stores identical outputs keyed on identical inputs. PAI precomputes reasoning across a decision space that covers many cases, not a lookup of past answers.
It’s not prompt or context caching. Prompt caching reduces prefill cost for repeated prompt prefixes, but the final answer is still generated by a live model on every request. Response caching stores the full output for identical inputs — closer, but still per-query memoization. PAI removes the live call from the served path entirely.
It’s not batch inference. Netflix precomputing your movie recommendations overnight is a decades-old pattern — the served artifact is a ranked list or numeric table. PAI precomputes reasoning: the artifact is authored by the LLM, encodes a decision space with fuzzy coverage, and treats abstention as a first-class outcome with a declared escalation path. Batch inference scores known items; PAI compiles judgment about a decision space that won’t be fully known until request time.
It’s not routing or cascades. Routing decides which model handles the request. PAI removes the model from the request path altogether.
It’s not Compiled AI. A 2026 paper from XY.AI Labs, Stanford, and Harvard defines Compiled AI as LLM-generated code artifacts that run deterministically without further model invocation. That’s one valid technique inside PAI, but PAI covers more than just code artifacts — rulesets, lookup tables, precomputed text, policy surfaces, routing maps — and it keeps escalation as a first-class option. (“Artifact” in the Compiled AI sense means generated code; in PAI it means any precomputed output of LLM reasoning.)
PAI also sits above implementation tooling like DSPy, LMQL, and guidance. Those are ways to author and optimize prompts and programs. PAI is the design pattern that decides where the resulting reasoning lives — at request time, or ahead of it.
I recognize this doesn’t apply to every situation. PAI fits best where the decision space is bounded and the reasoning is stable enough to precompute — rules-based systems, deterministic paths, decisions that don’t need to be re-derived on every request.
Required properties
Every PAI system has three required properties. Without all three, you have something simpler — a static dataset, a hand-written rule engine, or a prompt cache.
1. A versioned artifact. The output of ahead-of-time LLM reasoning lives in an inspectable, diffable, testable form. It has an ID, a generation timestamp, and a known input schema.
2. A regeneration cadence. The artifact has a refresh policy — hourly, daily, weekly, or triggered by an external event. This addresses the issue of “Won’t your ruleset go stale?” Yes, unless you regenerate it. Name the cadence. Show the last-refreshed date. Define the freshness window.
3. A declared escalation path. When the artifact can’t decide — novel input, expired freshness — the system has a documented, gated path for what happens next. Live LLM escalation is the most powerful option, but a deterministic fallback or an explicit abstention (“we don’t cover this; here’s why”) also count. What’s not allowed is a silent guess. In user-facing tools the legible form is opt-in with disclosed cost; in enterprise systems it may be policy-, budget-, or admin-gated. The contract is the same; the surface differs.
Patterns
PAI accommodates multiple patterns — different artifact types, refresh cadences, and escalation paths. Named patterns and worked examples live in the pattern catalog.
Three tools I’ve shipped with PAI
rightmodel.dev — model picker for coding tasks. Input: a coding task signal set. Decision logic: a deterministic ruleset mapping signals to model tiers — no LLM in the decision path. Artifact: the precomputed explanation layer — LLM-authored reasoning for each recommendation, versioned and served alongside the result. Cadence: refreshed on schedule when prices, models, or capabilities shift. Escalation path: opt-in “deep analysis” that calls a live LLM with cost disclosed before the user commits. Full PAI: all three required properties met.
cloudestimate.dev — sizes self-managed workloads across AWS, Google Cloud, and Microsoft Azure. Input: workload + region + cloud. Decision logic: vendor reference architectures mapped to instance tables. Artifact: precomputed sizing explanations and pricing data, committed as versioned JSON. Cadence: daily pricing snapshots and regenerated explanations via GitHub Actions; “Pricing data last refreshed” footer surfaces the staleness window. Escalation path: deterministic fallback — committed-term pricing computed against the same data; no live LLM call in the user flow. Full PAI: all three required properties met.
runwhere.dev — answers “stay on the hosted API, or run your own model?” Input: a four-question check — API spend, hosted model, traffic pattern, hard constraints. Decision logic: a precomputed boundary separating the API-default common case from the self-hosting exception set. Artifact: the boundary plus a precomputed comparison across managed endpoints, serverless GPU, always-on and batch GPU VMs, and owned hardware. Cadence: refreshed when prices, models, or constraints change. Escalation path: live LLM analysis reserved for close calls and likely outliers. Full PAI: all three required properties met.
When PAI fits
PAI fits when:
- the decision space is bounded or classifiable;
- the reasoning changes slower than request frequency;
- most requests fall into repeatable cases;
- low latency or cost predictability matters;
- auditability matters;
- the artifact can declare what it doesn’t cover;
- regeneration can be tested.
When PAI doesn’t fit
PAI doesn’t fit when:
- every request requires fresh world state;
- the task is highly personalized and context-heavy;
- correctness depends on large unseen context;
- the cost of regeneration exceeds saved inference;
- users expect open-ended reasoning;
- you cannot define coverage or abstention.
If those conditions hold, you want live inference, retrieval, or fine-tuning — not PAI.
Why this matters now
Token costs compound at scale. Cheap per call, expensive per million calls. Teams shipping at production volume are running into this wall right now. PAI moves reasoning out of the request, turning per-call cost into periodic regeneration cost.
Latency budgets are tight. Users don’t tolerate synchronous LLM calls in interfaces that used to feel instant. Every feature shipped with a live LLM call is a latency regression unless the reasoning lives somewhere else. PAI removes the LLM from the request path — the served artifact is as fast as a static file.
Auditability is becoming a buyer requirement. Enterprise and regulated industries do not accept “the model decided” as an audit trail. A versioned PAI artifact is inspectable, diffable, and testable by default.
PAI puts a name on a pattern emerging independently across teams. Shared vocabulary makes it easier to teach, evaluate, and compose.
Open questions
- What does it cost to keep the explanation layer fresh, and what does that buy you? RightModel is the testbed. The answer depends on regeneration frequency, decision space size, and how much live inference it displaces. Numbers forthcoming.
Contribute
If you’re shipping an LLM-powered tool and you feel that Token Consumption Anxiety, ask one question about your design:
Which parts of this reasoning could live in an artifact instead of in the request?
Concrete ways to engage:
- Pattern contributions — submit a PR to
patterns/with a worked example. - Worked examples — open an issue tagged
examplelinking to your shipped artifact. - Critique the definitions — open an issue tagged
discuss. Sharp critique is more useful than agreement.
Canonical home: precomputedai.com
Patterns and spec: github.com/PrecomputedAI/precomputed-ai
Worked examples: rightmodel.dev · cloudestimate.dev · runwhere.dev
Licensed CC BY 4.0. Cite as: Raquedan, R. (2026). Precomputed AI: Reason Ahead of Time, Serve Instantly. https://precomputedai.com
Last refreshed: 2026-05-17 — v0.6
This site is open source. Improve this page.